In this script I wanted to save public Facebook Pages post data into my local database. See source in github
The main.py script will setup the database structure, retrieve the data from the facebook graph api, then store it into your database.
If you would like only today’s post from the Facebook pages you can use the argument –t without this it will get all public posts available. You can also use -n (number of posts) to limit the amount of post to save.
You will also need to include the page names. Here is an example when you want to save all the public posts data for a page TacoBell.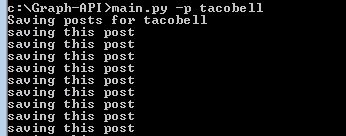
Here you only get today’s post:
To get multiple pages at once no coma is needed just add all the pages with a space in between.
main.py -p tacobell mcdonalds -t
main.py:
from time import sleep
from time import gmtime
from dateutil import parser
import datetime
from facebook import GraphAPI
import argparse, sys
from urlparse import parse_qs, urlparse
import mysql.connector
from mysql.connector import errorcode
from config import config, access_token
cnx = mysql.connector.connect(**config)
cursor = cnx.cursor()
table_name = 'pages'
table = ("CREATE TABLE `pages` ("
" `id` int(11) NOT NULL AUTO_INCREMENT,"
" `page_name` varchar(40) NOT NULL,"
" `post_id` varchar(40) NOT NULL,"
" `created_time` datetime NOT NULL,"
" `message` TEXT NOT NULL,"
" PRIMARY KEY (`id`)"
") ENGINE=InnoDB")
def create_db_table():
cursor.execute('SHOW DATABASES;')
all_dbs = cursor.fetchall()
if all_dbs.count((config['database'],)) == 0:
print("Creating db")
cursor.execute(
"CREATE DATABASE {} DEFAULT CHARACTER SET 'utf8'".format(config['database']))
cursor.execute('USE %s;' % config['database'])
cursor.execute("SHOW TABLES;")
all_tables = cursor.fetchall()
if all_tables.count(('pages',)) == 0:
print("creating table")
cursor.execute(table)
add_message = ("INSERT INTO pages "
"(post_id, page_name, created_time, message) "
"VALUES (%s, %s,%s, %s)")
def insert_post(post_id, page_name, created_time, message):
cursor.execute("SELECT * FROM pages WHERE post_id=%s;", (post_id,))
if cursor.fetchall():
print("already saved this post")
return False
print('saving this post')
cursor.execute(add_message, (post_id, page_name, created_time, message))
cnx.commit()
import calendar
from datetime import datetime, timedelta
def make_it_good(s):
res = ""
for ch in s:
try:
res += ch.decode('utf8')
except Exception as e:
pass
return res
def utc_to_local(utc_dt):
# get integer timestamp to avoid precision lost
timestamp = calendar.timegm(utc_dt.timetuple())
local_dt = datetime.fromtimestamp(timestamp)
assert utc_dt.resolution >= timedelta(microseconds=1)
return local_dt.replace(microsecond=utc_dt.microsecond)
def save_posts(page, num_post=None, only_today=False):
if not num_post:
num_post = 1000000000
graph = GraphAPI(access_token)
arguments = {}
total = 0
num_saved = 0
while 1:
try:
posts = graph.get_connections(page, 'posts', **arguments)
except Exception as e:
try:
sleep(3)
posts = graph.get_connections(page, 'posts', **arguments)
except Exception as e:
print("Retrieved a total of %d posts" % total)
print("But some error happened after that")
print("This is the error")
print(e)
print("Breaking...")
break
next = None
if 'paging' in posts:
next = posts['paging']['next']
posts = posts['data']
total += len(posts)
any = False
for post in posts:
if 'message' in post:
created_time = parser.parse(post['created_time'])
created_time = utc_to_local(created_time)
today = datetime.now()
if only_today:
if today.year == created_time.year and today.month == created_time.month and \
today.day == created_time.day:
any = True
else:
continue
num_saved += 1
insert_post(post['id'], page, created_time, make_it_good(post['message']))
if only_today and not any:
break
if next:
qs = parse_qs(urlparse(next).query)
arguments = {'limit': qs['limit'][0], 'until': qs['until'][0]}
else:
break
print('done')
print('Saved total of %d posts' % num_saved)
create_db_table()
def main():
parser = argparse.ArgumentParser(
description='Saving facebook pages post to a mysql db ')
parser.add_argument("-p", nargs='+', help="Please specify the name of page")
parser.add_argument('-n',
help="Please specify number of posts you want to save to db( if no argument is supplied all "
"posts will be saved, note this might take some time")
parser.add_argument('-t', action='store_true', help="Specify if you want to get only today posts")
args = parser.parse_args()
only_today = args.t
pages = args.p
n = args.n
if not pages:
parser.print_usage()
sys.exit(1)
if n:
n = int(n)
if only_today:
print("Saving today posts")
for page in pages:
print("Saving posts for %s" % page)
save_posts(page, n, only_today)
if (__name__ == '__main__'):
main()
Config file:
config={
'user':'root',
'host':127.0.0.1,
'password':'mypass',
'database':'analytics'
}
access_token='token'